Inteligencia Artificial contra el Fraude: Análisis de transacciones de tarjetas de crédito
Exploratory Data Analysis
Shallow Machine Learning Models
Random Forest
Dimensionality Reduction Techniques
Abordamos el desafío de predecir transacciones fraudulentas en tarjetas de crédito, analizando un dataset europeo de 2023. Aplicamos técnicas como PCA y Random Forest, y descubrimos que, a pesar de presentarse como real, el dataset fue generado artificialmente.
This dataset contains credit card transactions made by European cardholders in the year 2023. It comprises over 550,000 records, and the data has been anonymized to protect the cardholders’ identities. The primary objective of this dataset is to facilitate the development of fraud detection algorithms and models to identify potentially fraudulent transactions. – From Kaggle’s dataset page
Context
Tenemos un dataset anonimizado con transacciones de tarjetas de crédito realizadas en 2023. Algunas de estas transacciones han sido etiquetadas como fraudulentas. Una transacción se considera fraudulenta cuando ha sido realizada sin el consentimiento del dueño de la tarjeta, como ocurriría tras un robo.
Objective
Desarrollar un modelo capaz de detectar las transacciones fraudulentas.
1b. Entendimiento de los datos
Para empezar, importamos las librerías que vamos a utilizar:
Pandas: Pandas es una biblioteca esencial en la ciencia de datos que proporciona estructuras de datos flexibles y eficientes, como DataFrames, para el análisis y manipulación de datos tabulares. Es ampliamente utilizada para limpiar, transformar y analizar datos, lo que la convierte en una herramienta fundamental para la preparación de datos en proyectos de ciencia de datos.
Scipy: Scipy es una biblioteca que se construye sobre NumPy y ofrece una amplia variedad de módulos y funciones especializadas para aplicaciones científicas y matemáticas. Incluye herramientas para estadísticas, optimización, álgebra lineal y procesamiento de señales, lo que la hace esencial en la investigación y el análisis de datos en ciencia de datos.
Scikit-learn (sklearn): Es una biblioteca clave para el aprendizaje automático en Python, ofreciendo una amplia variedad de algoritmos y herramientas para clasificación, regresión y agrupamiento.
Plotly Express: Plotly Express es una biblioteca de visualización de datos que simplifica la creación de gráficos interactivos y visuales. Es especialmente útil en la exploración de datos y la comunicación de resultados en ciencia de datos, permitiendo a los científicos de datos crear visualizaciones informativas y atractivas con facilidad.
Aunque el texto principal está en español, los términos matemáticos, los títulos de secciones y el código están en inglés.
Esta práctica sigue el estándar internacional y ayuda a familiarizarse con el lenguaje técnico más utilizado en el campo de la ciencia de datos.
1b.1 Descripción de datos
El dataset consiste en un archivo csv con las siguientes columnas:
id: Identificador único para cada transacción
V1-V28: funciones anónimas que representan varios atributos de transacción (por ejemplo, hora, ubicación, etc.)
Amount: El monto de la transacción
Class: Etiqueta binaria que indica si la transacción es fraudulenta (1) o no (0)
No se nos aporta información de las unidades, más allá de Amount, que probablemente sean euros.
df.describe()
id
V1
V2
V3
V4
V5
V6
V7
V8
V9
...
V21
V22
V23
V24
V25
V26
V27
V28
Amount
Class
count
568630.000000
5.686300e+05
5.686300e+05
5.686300e+05
5.686300e+05
5.686300e+05
5.686300e+05
5.686300e+05
5.686300e+05
5.686300e+05
...
5.686300e+05
5.686300e+05
5.686300e+05
5.686300e+05
5.686300e+05
5.686300e+05
5.686300e+05
5.686300e+05
568630.000000
568630.0
mean
284314.500000
-5.638058e-17
-1.319545e-16
-3.518788e-17
-2.879008e-17
7.997245e-18
-3.958636e-17
-3.198898e-17
2.109273e-17
3.998623e-17
...
4.758361e-17
3.948640e-18
6.194741e-18
-2.799036e-18
-3.178905e-17
-7.497417e-18
-3.598760e-17
2.609101e-17
12041.957635
0.5
std
164149.486122
1.000001e+00
1.000001e+00
1.000001e+00
1.000001e+00
1.000001e+00
1.000001e+00
1.000001e+00
1.000001e+00
1.000001e+00
...
1.000001e+00
1.000001e+00
1.000001e+00
1.000001e+00
1.000001e+00
1.000001e+00
1.000001e+00
1.000001e+00
6919.644449
0.5
min
0.000000
-3.495584e+00
-4.996657e+01
-3.183760e+00
-4.951222e+00
-9.952786e+00
-2.111111e+01
-4.351839e+00
-1.075634e+01
-3.751919e+00
...
-1.938252e+01
-7.734798e+00
-3.029545e+01
-4.067968e+00
-1.361263e+01
-8.226969e+00
-1.049863e+01
-3.903524e+01
50.010000
0.0
25%
142157.250000
-5.652859e-01
-4.866777e-01
-6.492987e-01
-6.560203e-01
-2.934955e-01
-4.458712e-01
-2.835329e-01
-1.922572e-01
-5.687446e-01
...
-1.664408e-01
-4.904892e-01
-2.376289e-01
-6.515801e-01
-5.541485e-01
-6.318948e-01
-3.049607e-01
-2.318783e-01
6054.892500
0.0
50%
284314.500000
-9.363846e-02
-1.358939e-01
3.528579e-04
-7.376152e-02
8.108788e-02
7.871758e-02
2.333659e-01
-1.145242e-01
9.252647e-02
...
-3.743065e-02
-2.732881e-02
-5.968903e-02
1.590123e-02
-8.193162e-03
-1.189208e-02
-1.729111e-01
-1.392973e-02
12030.150000
0.5
75%
426471.750000
8.326582e-01
3.435552e-01
6.285380e-01
7.070047e-01
4.397368e-01
4.977881e-01
5.259548e-01
4.729905e-02
5.592621e-01
...
1.479787e-01
4.638817e-01
1.557153e-01
7.007374e-01
5.500147e-01
6.728879e-01
3.340230e-01
4.095903e-01
18036.330000
1.0
max
568629.000000
2.229046e+00
4.361865e+00
1.412583e+01
3.201536e+00
4.271689e+01
2.616840e+01
2.178730e+02
5.958040e+00
2.027006e+01
...
8.087080e+00
1.263251e+01
3.170763e+01
1.296564e+01
1.462151e+01
5.623285e+00
1.132311e+02
7.725594e+01
24039.930000
1.0
8 rows × 31 columns
Todas las columnas anónimas tienen una standard deviation de 1 y una mean centrada 0. Esto nos indica que han sido normalizadas.
df["Class"].value_counts()
Class
0 284315
1 284315
Name: count, dtype: int64
Existe el mismo número de muestras para cada clase.
Ideas destacadas
Las variables independientes han sido, como mínimo, normalizadas.
Existe el exactamente el mismo número de muestras para cada clase. Es un dataset perfectamente balanceado.
Podemos estar ante un dataset generado, en lugar de obtenido del mundo real. ¿Por qué?
Es muy difícil acceder a un dataset con más de 2500000 muestras donde realmente se haya identificado una transacción fraudulenta.
La falta de información especifica sobre la procedencia de los datos.
Esto es no es un problema. Generar datos es una opción válida (y a veces la única), existen ciertos escenarios donde la recolección de datos reales conlleva manejar datos sensibles. El único inconveniente estaría que el dataset se ha publicado como: “Transacciones con tarjeta de crédito realizadas por titulares de tarjetas europeos en el año 2023.”. Es decir, se da ha entender que se tratan de datos reales (en los que se ha anonimizado la información sensible).
2a. Preparación de los datos
2a.1 Typecasting
Comprobamos el tipo de datos de las columnas y los modificamos conforme nuestra descripción inicial.
Para las variables anónimas, hemos localizado gran cantidad de outliers, como cabría esperar. Se pueden hacer tres cosas con los outliers, siguiendo la mnemotecnia 3R: rectificar, retener o remover. En este caso, podemos estar ante valores atípicos genuinos, por tanto vamos a retenerlos.
En cuanto a la variable “Amount”, no existen outliers. Además hay una simetría perfecta entre ambas clases, lo que parece confirmar nuestra suposición previa sobre que estamos trabajando con datos generados.
2a.4 Variables con varianza cercana a cero
No existen variables con Zero & Near Zero Variance
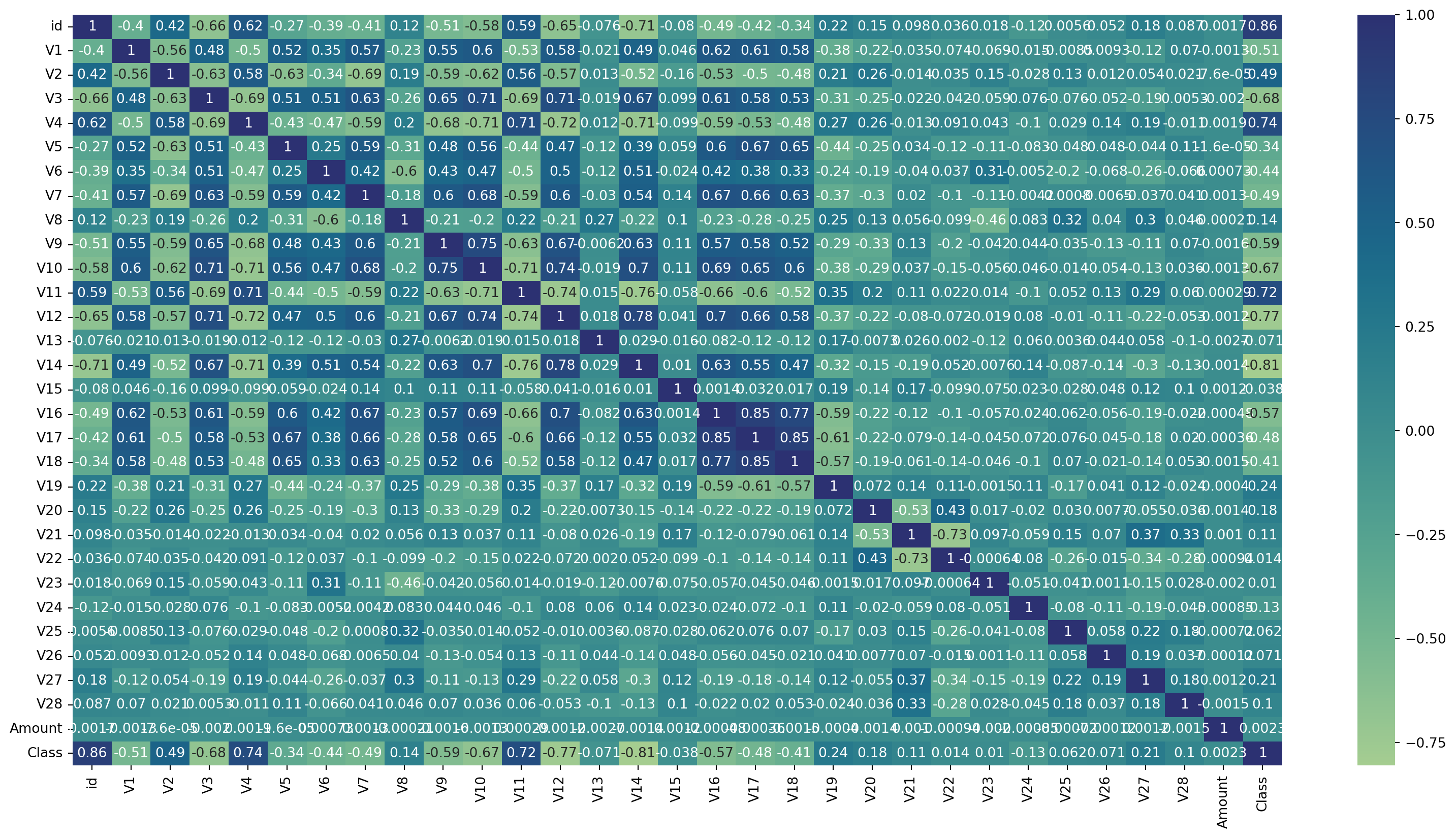
Correlaciones con “Class”: algunas variables ‘V’ muestran correlaciones moderadas con la variable ‘Class’, que representa si una transacción es fraudulenta o no. Estas variables pueden ser muy importantes para predecir el fraude.
La variable ’Amount: no muestra correlaciones fuertes con la mayoría de las otras variables, lo que sugiere que el monto de las transacciones no está directamente relacionado con las otras características en términos de correlación lineal.
Correlaciones fuertes: se observan algunas correlaciones fuertes entre las variables ‘V’. Esto puede indicar relaciones subyacentes significativas que podrían ser exploradas para comprender mejor la estructura de los datos.
Dado que algunas variables están altamente correlacionadas, podrían ser candidatas para técnicas de reducción de dimensiones como PCA, para simplificar el modelo sin perder información valiosa.
Representemos las variables con más correlación con la variable objetivo “Class”:
# Calculate the correlation matrixcorrelation_matrix = df.corr()# Select correlations with 'Class' variable excluding 'Class' itself and 'ID'class_correlations = correlation_matrix["Class"].drop(["Class", "id"])# Sort the variables by their absolute correlation with 'Class'sorted_correlations = class_correlations.abs().sort_values(ascending=False)
# Select the variables with the highest correlationselected_variables = sorted_correlations.head(4).index.tolist()print(f"selected_variables = {selected_variables}")# A stratified sample is created for the chartssample_df, _ = train_test_split(df, train_size=1000, stratify=df["Class"])
# Create the scatter matrixfig = px.scatter_matrix( sample_df, dimensions=selected_variables, color="Class", title="Scatter Matrix of Selected Variables",)fig.for_each_trace(lambda t: t.update(name="Fraudulent"if t.name =="1"else"Legitimate"))fig.show()
Ideas destacadas
Con las 28 variables anónimas, un estudio detallado de centralidad, dispersión, skewness y kurtosis no parece lo más adecuado. Recapitulando:
Algunas variables ‘V’ tienen correlaciones moderadas con la variable ‘Class’, lo que es importante para predecir el fraude.
Se observan correlaciones fuertes entre algunas variables ‘V’, lo que sugiere relaciones significativas. Podemos considerar la reducción de dimensionalidad.
La variable ‘Amount’ no tiene correlaciones fuertes con otras variables.
2c. Ingeniería de características
Vamos a construir varios conjuntos de datos y evaluaremos el rendimiento de los modelos. Utilizaremos 4 conjuntos:
El conjunto original
Un conjunto Threshold-Based
Dos conjuntos PCA
Los creamos a continuación:
2c.1 Feature Selection
Creamos el conjunto Threshold-Base seleccionando las variables cuyo valor absoluto en la correlación con “Class” sea mayor a 0.6
Realizamos Principal Component Analysis. Creamos dos nuevos conjuntos de datos.
# Select the features to be analyzed, which are columns "V1" to "V28"features = [f"V{i}"for i inrange(1, 29)]# Extract the selected features from the DataFrame 'df'x = df.loc[:, features].values# Perform Principal Component Analysis (PCA) with 2 componentspca = PCA(n_components=2)principalComponents = pca.fit_transform(x)# Create a new DataFrame to store the principal componentsprincipalDf = pd.DataFrame(data=principalComponents, columns=["pc1", "pc2"])# Concatenate the principal components with the 'Class' columnpca_2_df = pd.concat([principalDf, df[["Class"]]], axis=1)
# Create a stratified sample with 1000 data points for visualizationsample_df, _ = train_test_split(pca_2_df, train_size=1000, stratify=df["Class"])# Create a scatter plot using Plotly Express to visualize the principal componentsfig = px.scatter(sample_df, x="pc1", y="pc2", color="Class")# Update the legend names for clarityfig.for_each_trace(lambda t: t.update(name="Fraudulent"if t.name =="1"else"Legitimate"))fig.show()
# Perform Principal Component Analysis (PCA) with 6 componentspca = PCA(n_components=6)principalComponents = pca.fit_transform(x)# Create a new DataFrame to store the principal componentsprincipalDf = pd.DataFrame( data=principalComponents, columns=[f"pc{i}"for i inrange(1, 7)])# Concatenate the principal components with the 'Class' columnpca_6_df = pd.concat([principalDf, df[["Class"]]], axis=1)
# Create a stratified sample with 1000 data points for visualizationsample_df, _ = train_test_split(pca_6_df, train_size=1000, stratify=df["Class"])# Create the scatter matrixfig = px.scatter_matrix( sample_df, dimensions=[f"pc{i}"for i inrange(1, 7)], color="Class", title="Scatter Matrix of Selected Variables",)fig.for_each_trace(lambda t: t.update(name="Fraudulent"if t.name =="1"else"Legitimate"))fig.show()
original_df = df.drop(columns=["id"])# Assign the scaled values back to the "Amount" column in the original DataFrameamount_df = original_df[["Amount"]]sc = StandardScaler()scaled_amount = sc.fit_transform(amount_df)original_df["Amount"] = scaled_amount
Ideas destacadas
Vamos a comparar el rendimiento que podemos obtener con los siguientes datasets:
correlation_df, con las seis variables que tienen una correlación mayor a 0.6
pca_2_df, con dos componentes principales de PCA
pca_6_df, con seis componentes principales de PCA
original_df, el conjunto original (con 29 variables)
3. Modelos
Empecemos con los siguientes modelos de aprendizaje automático superficial:
Logistic Regression
Decision Tree
K-Nearest Neighbors
Naive Bayes
3.1 Modelos de aprendizaje automático superficial (Shallow Machine Learning Models)
# Create a bar plot to visualize the results, grouped by dataset and modelfig = px.bar( results_shallow_models_df, x="Dataset", y=["CV Accuracy", "CV Precision", "CV Recall", "CV F1 Score"], barmode="group", facet_col="Model",)# Configura el rango del eje y entre 0.8 y 1fig.update_yaxes(range=[0.8, 1])fig.show()
Fíjate que las gráficas se presentan con ZOOM en el eje Y
El valor más bajo de accuracy, que estamos viendo en las gráficas, está por encima del 90%
3.2 Random Forest with Hypertuning and Principal Component Analysis (PCA) with 3 components
Los resultados obtenidos con el datasetpca_2_df son muy buenos. Tenemos que recordar que en este conjunto de datos solo tenemos dos columnas.
Vamos a crear un dataset pero con 3 PCA y entrenar un Random Forest con selección de hiperparámetros.
# Perform Principal Component Analysis (PCA) with 3 componentspca = PCA(n_components=3)principalComponents = pca.fit_transform(x)# Create a new DataFrame to store the principal componentsprincipalDf = pd.DataFrame( data=principalComponents, columns=[f"pc{i}"for i inrange(1, 4)])# Concatenate the principal components with the 'Class' columnpca_3_df = pd.concat([principalDf, df[["Class"]]], axis=1)
pca_3_df.head()
pc1
pc2
pc3
Class
0
2.190825
-0.165314
0.265893
0
1
2.085009
0.355739
0.168428
0
2
2.282798
-0.521145
-0.361626
0
3
2.694661
0.107729
-0.255410
0
4
2.048980
-0.354799
0.937397
0
Al trabajar con 3 dimensiones (variables) es muy interesante crear una representación gráfica interactiva.
# Create a stratified sample with 5000 data points for visualizationsample_df, _ = train_test_split(pca_3_df, train_size=5000, stratify=df["Class"])fig = px.scatter_3d( sample_df, x="pc1", y="pc2", z="pc3", color="Class", color_discrete_map={0: "blue", 1: "red"}, labels={"Class": "Transaction Type"}, title="3D PCA Scatter Plot",)# Update the legend names for clarityfig.for_each_trace(lambda t: t.update(name="Fraudulent"if t.name =="1"else"Legitimate"))fig.show()
La gráfica es interactiva
Puedes rotarla libremente en cualquier eje para entender mejor los datos.
Starting hyperparameter search for Random Forest...
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[CV] END bootstrap=True, criterion=gini, max_depth=20, n_estimators=200; total time= 2.2min
[CV] END bootstrap=False, criterion=gini, max_depth=20, n_estimators=200; total time= 3.1min
[CV] END bootstrap=True, criterion=gini, max_depth=20, n_estimators=200; total time= 2.2min
[CV] END bootstrap=True, criterion=gini, max_depth=20, n_estimators=500; total time= 5.4min
[CV] END bootstrap=True, criterion=gini, max_depth=20, n_estimators=500; total time= 5.2min
[CV] END bootstrap=False, criterion=gini, max_depth=20, n_estimators=200; total time= 3.1min
[CV] END bootstrap=False, criterion=gini, max_depth=20, n_estimators=200; total time= 3.1min
[CV] END bootstrap=True, criterion=gini, max_depth=20, n_estimators=200; total time= 2.2min
[CV] END bootstrap=True, criterion=gini, max_depth=20, n_estimators=500; total time= 5.3min
[CV] END bootstrap=False, criterion=gini, max_depth=20, n_estimators=500; total time= 7.0min
[CV] END bootstrap=False, criterion=gini, max_depth=20, n_estimators=500; total time= 7.1min
[CV] END bootstrap=False, criterion=gini, max_depth=20, n_estimators=500; total time= 7.0min
Hyperparameter search completed in: 25 minutes 22 seconds
/home/mike/.anaconda3/envs/data_road/lib/python3.11/site-packages/joblib/externals/loky/process_executor.py:752: UserWarning:
A worker stopped while some jobs were given to the executor. This can be caused by a too short worker timeout or by a memory leak.
# Display the resultsfor metric, value in results.items():if metric !="Best Parameters":print(f"{metric}: {value:.3f}")else:print(f"{metric}: {value}")# Convert the results into a DataFrame for tabular representationresults_random_forest_df = pd.DataFrame([results])
Best Parameters: {'bootstrap': False, 'criterion': 'gini', 'max_depth': 20, 'n_estimators': 500}
Accuracy: 0.990
Precision: 1.000
Recall: 0.981
F1 Score: 0.990
Ideas destacadas
Los modelos que mejor funcionan son:
Decision Tree
K-Nearest Neighbors
Lo más interesante nos lo muestran los datasets. Recordemos que variables contiene cada uno:
correlation_df, con las seis variables que tienen una correlación mayor a 0.6
pca_2_df, con dos componentes principales de PCA
pca_6_df, con seis componentes principales de PCA
original_df, el conjunto original (con 29 variables)
Qué hemos descubierto:
Pese a contar con 23 dimensiones menos, tanto correlation_df como pca_6_df logran unos resultados similares al dataset original. Eso significa que mediante las técnicas de reducción de dimensionalidad han funcionado correctamente logrando mantener la información relevante.
Los resultados obtenidos con pca_2_df son muy buenos para haberlos obtenido mediante 2 dimensiones.
Por último, hemos creado un dataset con 3 PCA y entrenado un modelo Random Forest (con selección de hiperparámetros). Este enfoque es el que mejor resultado nos ha entregado. Vamos a explorarlo a continuación.
4. Evaluación
4.1 Medidas de precisión del modelo
Comparemos la curva ROC de algunos de los modelos
# Display the confusion matrix and classification reportprint(f"Confusion Matrix:\n{conf_matrix}\n")print(f"Classification Report:\n{class_report}\n")# Save the results in a DataFrame for tabular representationresults = {"Accuracy": [accuracy],"Precision": [precision],"Recall": [recall],"F1 Score": [f1],"ROC AUC": [roc_auc_best],}results_random_forest_df = pd.DataFrame(results)
Hemos descubierto que, aunque no se anuncia como tal, estamos trabajando con un conjunto de datos que ha sido generado (no recolectado). Esto no es un problema. Generar datos es una opción válida (y a veces la única); existen ciertos escenarios donde la recolección de datos reales conlleva manejar datos sensibles. El único inconveniente estaría en que el dataset se ha publicado como: “Transacciones con tarjeta de crédito realizadas por titulares de tarjetas europeos en el año 2023”. Es decir, se da a entender que se tratan de datos reales (en los que se ha anonimizado la información sensible).
Hemos descubierto que varias de las variables mantienen una relación lineal. También que la variable “Amount” aporta poca información sobre el tipo de transacción (cosa que sería poco habitual si estuviésemos trabajando con un dataset real).
5.2 Sobre el rendimiento de los modelos
Hemos creado nuevos datasets reduciendo la dimensionalidad del original. Estos nuevos datasets se han construido seleccionando las seis componentes principales de PCA o las seis variables que tienen una correlación mayor a 0.6. La ejecución de los modelos sobre estos conjuntos de datos ha mostrado un rendimiento similar al obtenido al utilizar las 29 dimensiones del conjunto original.
El dataset creado únicamente con dos componentes principales de PCA ha arrojado unos resultados sorprendentes. Por ello, hemos creado un dataset con 3 PCA y entrenado un modelo Random Forest (con selección de hiperparámetros). Este enfoque es el que mejor resultado nos ha entregado, con un accuracy en torno al 99% y una superficie bajo la curva ROC cercana al 0.99.
De todos modos, cabe señalar que modelos más sencillos como Logistic Regression han logrado resultados muy competitivos con una complejidad inferior a Random Forest (con selección de hiperparámetros).